Flume - Basic Concept and Usage
Flume的基本概念和使用
基本概念
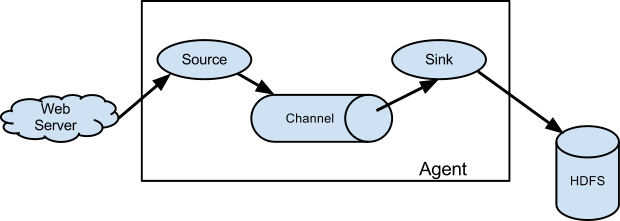
| 组件 | 功能 |
|---|---|
| Agent | 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
| Client | 生产数据,运行在一个独立的线程。 |
| Source | 从Client收集数据,传递给Channel。 |
| Sink | 从Channel收集数据,运行在一个独立线程。 |
| Channel | 连接 sources 和 sinks ,这个有点像一个队列。 |
| Events | 可以是日志记录、 avro 对象等。 |
使用
运行: bin/flume-ng agent --conf conf --conf-file conf/flumeconfig.properties -name a1
thrift -> flume -> kafka/hdfs
通过thrift获取数据,在双推kafka和hdfs
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = thrift
a1.sources.r1.threads = 5
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 1234
a1.sources.r1.selector.type = replicating
# 重复发送
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://host.ip:54310/path/%y-%m-%d/%{header-key}/
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = test_hdfs
a1.sinks.k1.hdfs.rollInterval = 86400
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.idleTimeout= 0
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.maxOpenFiles = 1000
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.topic = test_topic
a1.sinks.k2.kafka.bootstrap.servers = kafkaip1:9092,kafkaip2:9092,kafkaip3:9092
a1.sinks.k2.kafka.flumeBatchSize = 1000
a1.sinks.k2.kafka.partitionIdHeader = h
a1.sinks.k2.kafka.producer.acks = 1
a1.sinks.k2.kafka.producer.linger.ms = 1
a1.sinks.k2.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 5000
a1.channels.c2.type = memory
a1.channels.c2.capacity = 10000
a1.channels.c2.transactionCapacity = 5000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
kafka -> flume -> elasticsearch
从kafka拉取数据,推入ES,使用三个es sink提高速度
# Name the components on this agent
a2.sources = k1
a2.sinks = e1 e2 e3
a2.channels = c1
# Describe/configure the source
a2.sources.k1.channels = c1
a2.sources.k1.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.k1.kafka.topics = test_topic
a2.sources.k1.kafka.bootstrap.servers = kafkaip1:9092,kafkaip2:9092,kafkaip3:9092
a2.sources.k1.batchSize = 1000
a2.sources.k1.batchDurationMillis = 1000
# Describe/configure the source
a2.sinks.e1.channel = c1
a2.sinks.e1.type = com.frontier45.flume.sink.elasticsearch2.ElasticSearchSink
a2.sinks.e1.hostNames = es_ip1,es_ip2,es_ip3,es_ip4
a2.sinks.e1.indexName = flume
a2.sinks.e1.indexType = flume
a2.sinks.e1.clusterName = elasticsearch
a2.sinks.e1.batchSize = 1000
a2.sinks.e1.ttl = 5d
a2.sinks.e2.channel = c1
a2.sinks.e2.type = com.frontier45.flume.sink.elasticsearch2.ElasticSearchSink
a2.sinks.e1.hostNames = es_ip1,es_ip2,es_ip3,es_ip4
a2.sinks.e2.indexName = flume
a2.sinks.e2.indexType = flume
a2.sinks.e2.clusterName = elasticsearch
a2.sinks.e2.batchSize = 1000
a2.sinks.e2.ttl = 5d
a2.sinks.e3.channel = c1
a2.sinks.e3.type = com.frontier45.flume.sink.elasticsearch2.ElasticSearchSink
a2.sinks.e1.hostNames = es_ip1,es_ip2,es_ip3,es_ip4
a2.sinks.e3.indexName = flume
a2.sinks.e3.indexType = flume
a2.sinks.e3.clusterName = elasticsearch
a2.sinks.e3.batchSize = 1000
a2.sinks.e3.ttl = 5d
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 20000
a2.channels.c1.transactionCapacity = 5000
#a2.channels.c1.type = file
#a2.channels.c1.checkpointDir = /home/path/channel/checkpoint
#a2.channels.c1.dataDirs = /home/path/channel/data
问题总结
Flume 1.7 连接 ES 2.x 不兼容
出现错误:java.lang.NoSuchMethodError: org.elasticsearch.common.transport.InetSocketTransportAddress.
Kafka source 出现 Outofmemory 然后崩溃
原因:JVM 默认堆栈空间只有20M,需要加大,具体方法: 修改 conf/flume-env.sh 添加 JAVA_OPTS=”-Xms8192m -Xmx8192m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit” 将空间加到 8G
数据积压导致接收停止
原因是channel空间已满,通常是sink速度太慢导致,如果是file channel可以调大相关参数,但是无法避免
对接带有权限控制的Hadoop
-
将 hadoop/lib 下的 jar 文件移动到 flume/lib 下,或者在 flume/conf/flume-env.sh 中添加 FLUME_CLASSPATH
-
复制 hadoop/conf/hadoop-site.xml 和 hadoop-default.xml 到 flume/conf
-
修改 flume/conf 下的 hadoop 配置:mv hadoop-site.xml core-size.xml && mv hadoop-default.xml hdfs-site.xml
可能还会出现一些jar缺失的情况,需要自行下载添加
Flume的event header
使用kafka sink发送结果时,如果header中有 key 标签,则会以此作为kafka的partition依据,同理,当Spark再从kafka拉取数据时,也可以直接利用 key 来进行操作,比如 rdd.map(event => (event.key(), event.value())) 使用hdfs sink保存结果时,可以使用header中的标签来作为路径,例如hdfs://IP:port/path/%y-%m-%d/%{host} 另外,由于有header的存在,数据可以进行压缩,将重复的内容提取到header中,同时适当增加一个事件中数据的大小(不能超过1M,否则影响Kafka传输),可以提高处理效率。